
Thanks to Knarik Mheryan and Hrant Khachatrianfor co-writing this blogpost.
YerevaNN is a non-profit computer science and mathematics research lab based in Yerevan, Armenia. The lab’s main research interests are focused around machine learning algorithms and machine learning for biomedical data. YerevaNN also spends significant effort on supervision of student projects in order to support the up and coming Armenian scholars.
YerevaNN collaborates with University of Southern California — focused on low-resource learning problems, ENSAE / ParisTech on theoretical statistics problems, biologists and chemists from around the world on ML applications in various biomedical problems. YerevaNN has publications at ACL, CVPR, WMT, Annals of Statistics and Nature Scientific Data among others.
We traditionally onboard new teammates with a task to reproduce a well-known paper. This allows us to both introduce them to our internal systems, codebase, resources as well as it’s a great leeway into the problems they are going to focus on as part of their research at YerevaNN. This is a story about how Knarik Mheryan has gotten started at YerevaNN and how Aim has helped her in the process.
The Challenges
Model selection for cross-lingual transfer
Deep learning has enabled high-accuracy solutions to a wide variety of NLP tasks.. As these models are trained primarily on English corpora, they aren’t readily applicable or available for other human languages (due to the lack of labeled data).
One approach to solve this problem is to pre-train a model on an unlabeled multilingual dataset in an unsupervised fashion, then fine-tune it only on English labeled data for the given NLP task. It turns out the model’s performance on the target languages is strong, even though the model is fine-tuned only on English data.
Model selection is a crucial step in this approach. When fine-tuning on English data with different hyperparams and seeds we are left with a set of models. The challenge is to select the model with the highest performance (e.g. F1 score) in the target language.
In 2021, Yang Chen and Alan Ritter, have published a paper in EMNLP that tries to address this problem. Knarik Mheryan’s first task at YerevaNN has been to reproduce this work as part of the ML Reproducibility Challenge 2021.
Reproducing the study
A common tactic has been to select models that perform well on the English data. This paper shows that the accuracy of models on English data does not always correlate well with the target language performance. To reproduce this, we have fine-tuned 240 models on a Named Entity Recognition task.
The dimensionality of these experiments is high. So analyzing several 100 models is not a trivial task and it can take hours when comparing them with traditional tools. At YerevaNN we have been using Aim as it allows us to compare 1000s of high-dimensional (all metrics, hyperparams and other metadata) experiments in a few clicks.
The Solution
Using Params Explorer to compare models
Params explorer allows us to directly compare the models with one view and with a few clicks. We have tracked the F1 scores for all models, languages. Using Aim’s context makes it easy to add additional metadata to the metrics (such as lang=”fr”) so there is no need to bake that data into the name.
We have selected two hyperparameters of interest and F1 scores of 5 languages of interest. This one view shows all the models (each curve is a model) at once and we can compare them relative to selected hyperparams and metrics. (see Figure 1)
More importantly, the plot below shows that the best performing model on English data (F1 lang=”en”) certainly doesn’t perform well on German, Spanish, Dutch and Chinese. The red bold curve represents the best model on the English dataset.
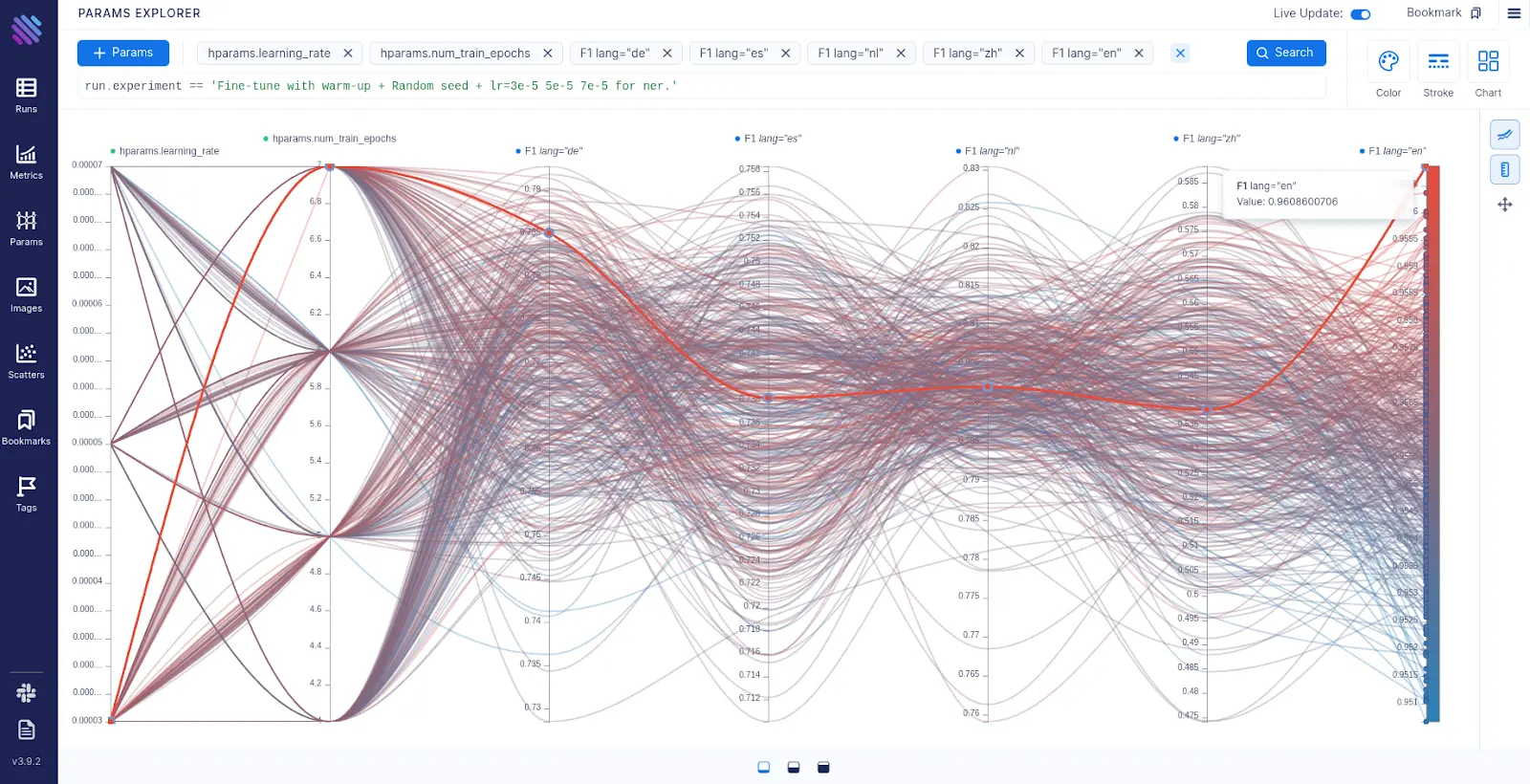
Figure 1: Aim’s Params plot for hundreds of fine-tuned models. Each curve corresponds to a single model with some hyperparameters and random seeds. Each vertical axis shows the model’s hyperparameters or the F1 scores for some language (German, Spanish, Dutch, Chinese, English).
\ It took us only a few clicks to see this key insight.
And this makes a couple of hours of work into something that’s less than a minute.
Qualitative metrics comparison with
Metrics Explorer
Catastrophic Forgetting on the best Eng-based model
In our pursuit of understanding why models behave that way, we have tracked F1 scores across 60 epochs for the model that performs best on the English dataset. The Figure 2 below shows the behavior of F1 scores for 5 different languages (German, Spanish, Dutch, Chinese and English).
The red line on Figure 2 represents the evaluation on English data. There is a clear difference in performance between the languages. Effectively Aim shows that the model overfits on English and what the ‘Catastrophic forgetting’ looks like.
Notably, the Chinese (orange) gets worse faster than the other languages. Possibly because there are major linguistic differences between Chinese and the rest of the languages.
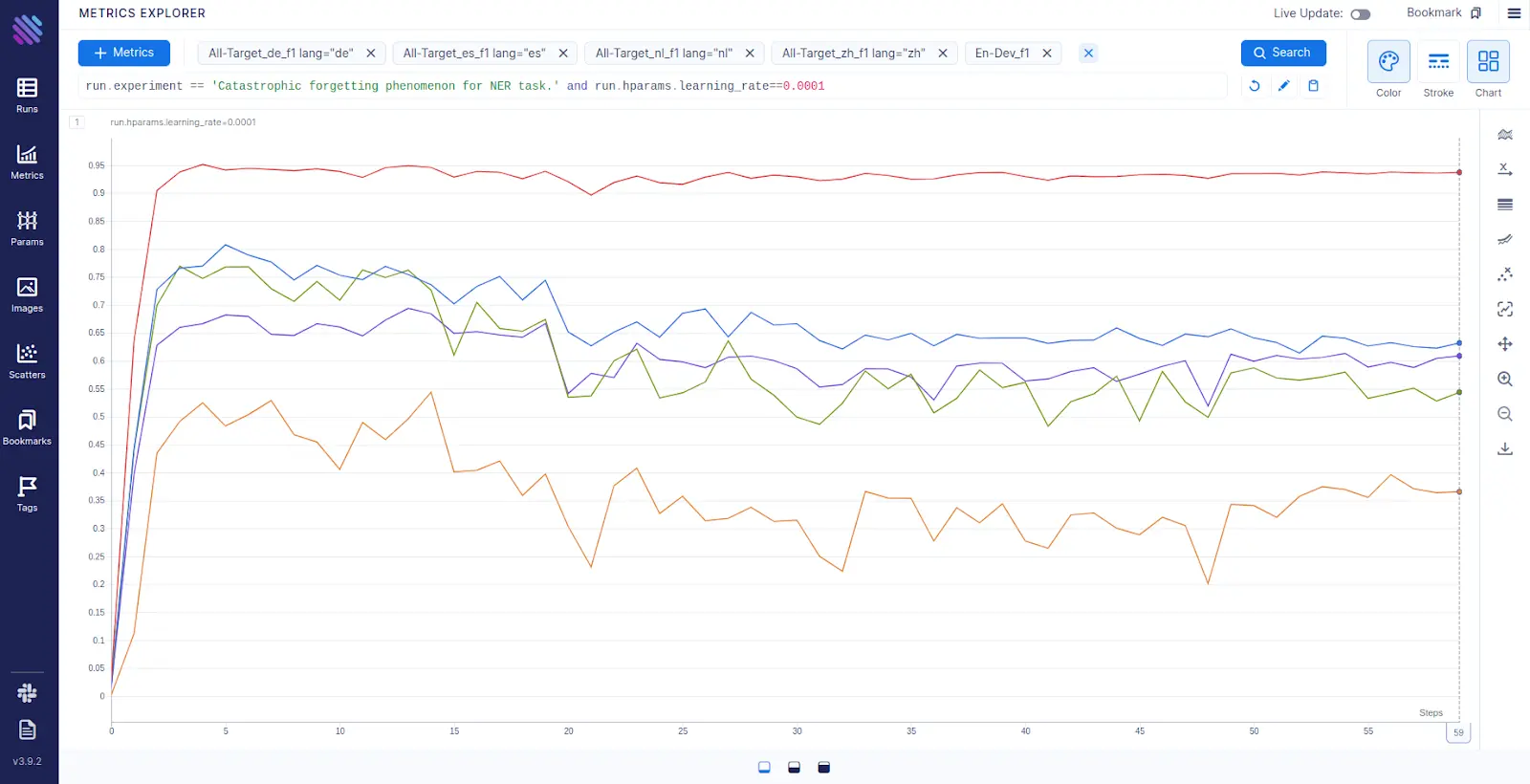
Figure 2: Visualization of the Catastrophic forgetting phenomenon. Evaluations on 5 languages development datasets for 60 epochs after fine-tuning the model on the English training data. The languages are English (red), Dutch (blue), German (green), Spanish (violet), and Chinese (orange).
Proposed model selection algorithm analysis
We reproduce the paper in two phases.
- First, we have created candidate models by fine-tuning them on English labeled data and checked their performance on the proposed 5 target languages.
- Second, we are going to build the algorithm for model selection — proposed in the paper and verify if it works better than the conventional methods.
Analyzing the Learning Rates
Aim’s Metric Explorer has allowed us to analyze the fine-tuning process through all the runs. In Figure 3, each line is a run with a specific target language, hyperparameter and random seed. Here we group runs by learning rate giving them the same color.
With Aim we frequently group runs into different charts. In this case we have grouped the metrics into charts by language . This allows us to visualize the fine-tuning with different learning rates per language.
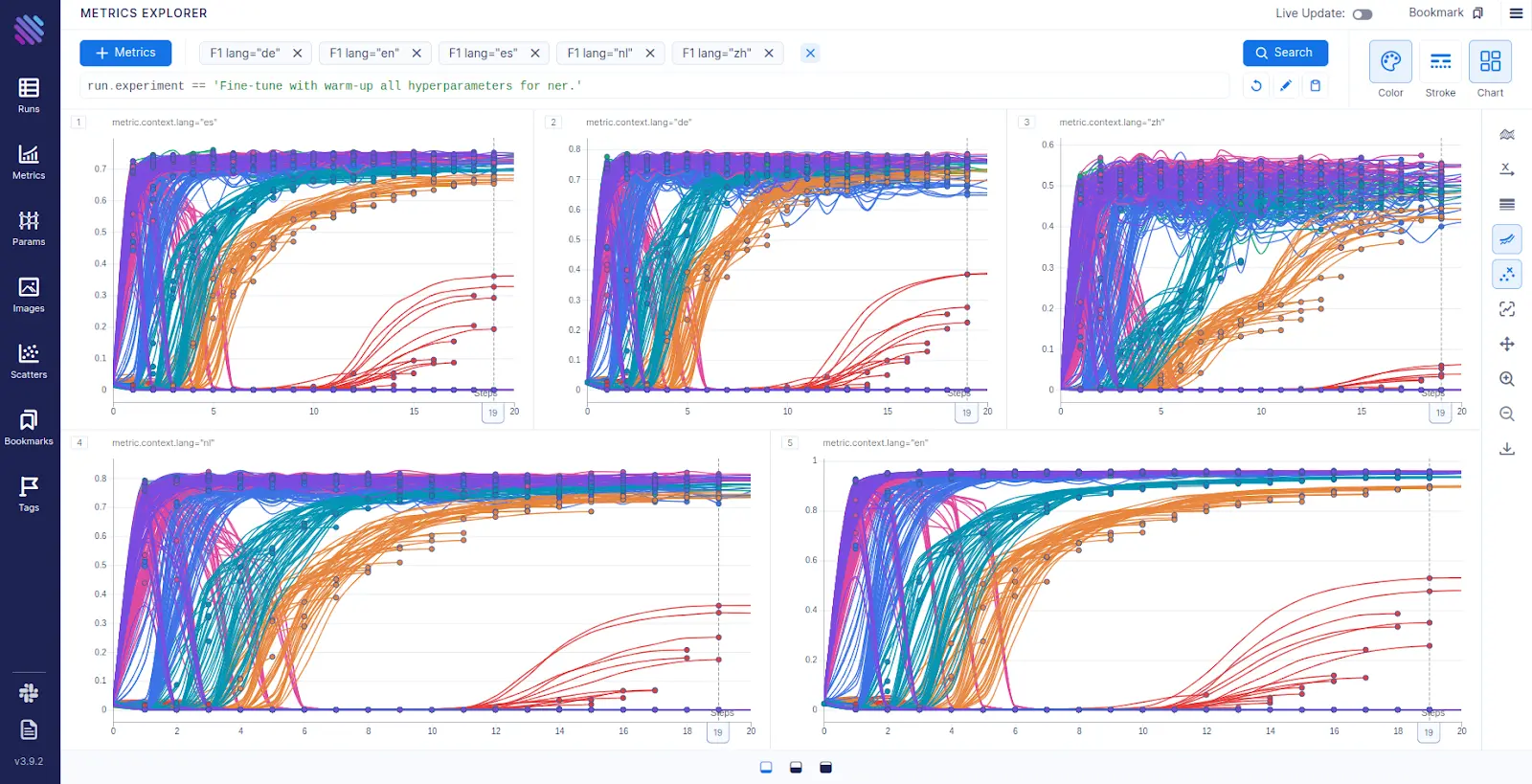
Figure 3: Visualization of the fine-tuning process with different learning rates and random seeds for Spanish, German, Chinese, Dutch and English languages.
With one more click, we aggregate runs of the same group (grouped by learning rate through all seeds). The aggregation helps us to see the trends of the F1 metrics collected across epochs.
From Figure 4 it is clear that all models with very small learning rates (red) barely learn anything in 20 epochs.
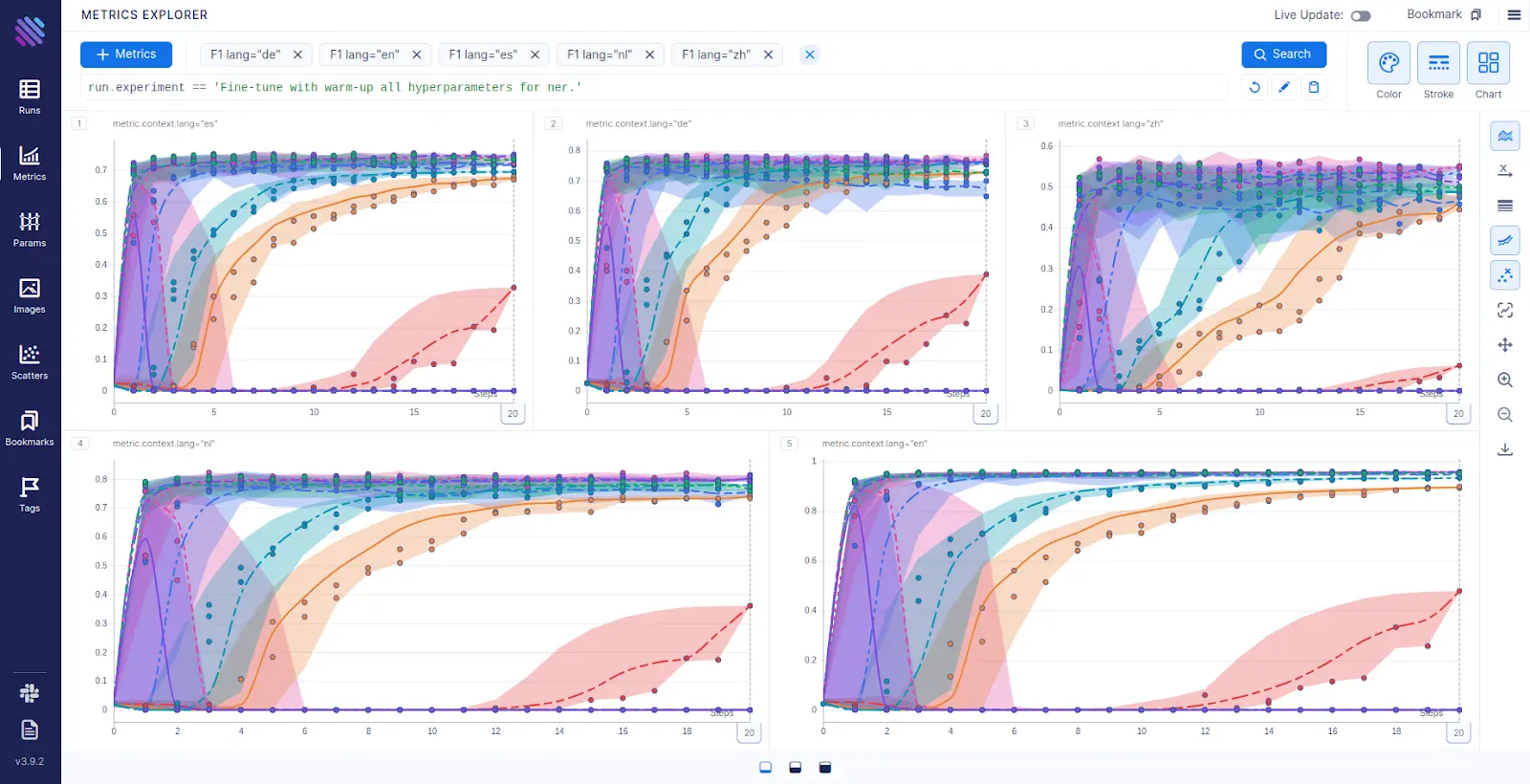
Figure 4: Visualization of the fine-tuning process aggregated by learning rates through different random seeds. Lines through highlighted intervals are medians from runs with different seeds. Each chart plots the fine-tuning process for a particular language (Spanish, German, Chinese, Dutch and English)
In this paper the authors suggest an alternative strategy for model selection named Learned Model Selection (LMS). LMS is a neural network based model that learns to score the compatibility between a fine-tuned model and a target language. According to the paper, this method consistently selects better models than English development data across the 4 target languages.
For this final step we have also calculated the LMS scores for each model and have used Aim Params Explorer to compare the new and old methods for their efficiency. By just selecting the params and metrics we have produced the Figure 5 on Aim. Each highlighted curve in Figure 5 corresponds to one of the model candidates. With the old method (with the English axis) the best candidate F1 on the English axis is 0.699. On the other hand, if we select by the new algorithm (with LMS score axis), the F1 score would be 0.71, which is indeed higher than with the English candidate model.
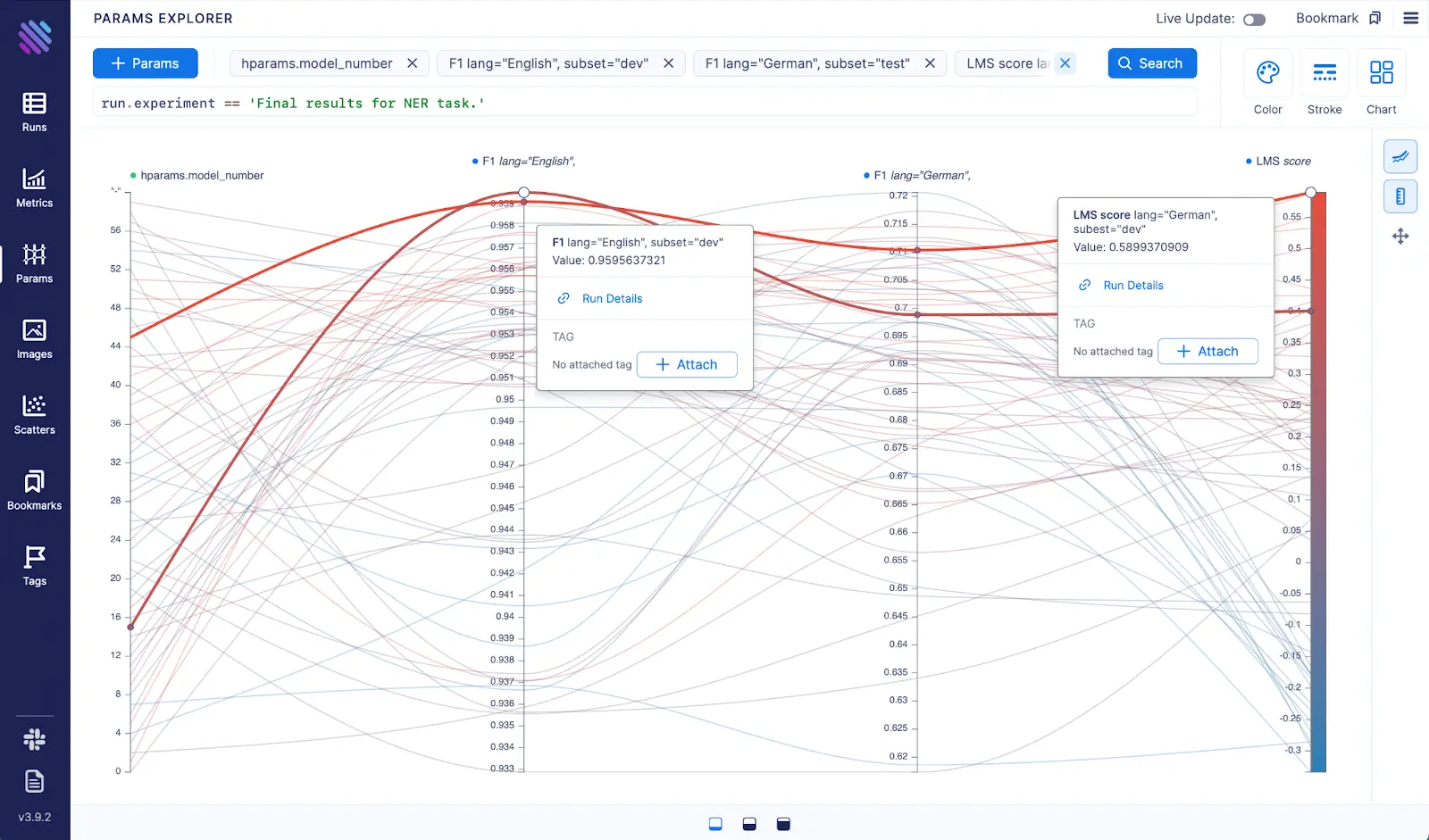
Figure 5: Visualization of the final process of model selection. The most left axis is the model number (like id) from 0 to 59. ‘F1 lang=”English”‘ is the F1 score on the English development data. ‘F1 lang=”German”‘ is the F1 score on the German test data. ‘LMS score’ is the ranking score provided by LMS, the algorithm proposed in the paper, the higher the better.
With Aim our experiments analysis at YerevaNN has become order of magnitude faster due to intuitive, beautiful and fast UI and the Aim explorers. The team at YerevaNN uses Aim on a daily basis to analyze their experiments.
Learn More
Aim is on a mission to democratize AI dev tools.
We have been incredibly lucky to get help and contributions from the amazing Aim community. It’s humbling and inspiring 🙌
Try out Aim, join the Aim community, share your feedback, open issues for new features, bugs.
This article was originally published on Aim Blog. Find more in depth guides and details of the newest releases there.