Nov 16, 2023
AI Observability with AimOS: A Deep Dive into the LlamaIndex Observer App

Welcome to the world of seamless tracking and visualization! LlamaIndex Observer, a tool that unites the robust capabilities of LlamaIndex with the blazingly fast AimOS. This integration offers a full-featured platform for effectively monitoring and understanding every detail in your LlamaIndex environment.
In this guide, we're going to highlight the main aspects of the LlamaIndex Observer application, with a special focus on its Trace page, a key component within the LlamaIndex Observer package in Aim.
LlamaIndex + AimOS = ❤
Imagine being able to see everything that happens in your LlamaIndex system from a high-level perspective. The LlamaIndex Observer makes this possible by using AimOS to provide a detailed record of each interaction.
AimOS 🔍 — A user-friendly observability platform for AI systems. It's adaptable, scalable, and versatile.
With AimOS, you can set up various types of AI monitoring applications, like experiment tracking, production monitoring, and usage analysis.
Now, let’s see how it works with an example!
Putting LlamaIndex Observer into Action: A Step-by-Step Guide
We'll now look at a hands-on example. We'll use a Python script to interact with LlamaIndex and observe how LlamaIndex Tracker records each action. This example demonstrates the smooth interaction between AimOS and LlamaIndex.
Before starting with the script, ensure AimOS is installed and set up. If you need to install it, visit AimOS repository for the guidelines.
Sample Script
1. Importing Required Modules
First we’ll start by importing the necessary Python modules for file manipulation, HTTP requests, and working with LlamaIndex and AimOS.
import os
from pathlib import Path
import requests
from aimstack.llamaindex_observer.callback_handlers import GenericCallbackHandler
from llama_index import ServiceContext, SimpleDirectoryReader, VectorStoreIndex
from llama_index.callbacks.base import CallbackManager2. Downloading Paul Graham's Essay
In this step, the script downloads Paul Graham's essay from a given URL and saves it locally in a specified directory.
It’s important to ensure that the essay is successfully downloaded before moving on to the next steps. Next, we will be asking questions referring this essay.
paul_graham_essay_url = "<https://raw.githubusercontent.com/run-llama/llama_index/main/docs/examples/data/paul_graham/paul_graham_essay.txt>"
response = requests.get(paul_graham_essay_url)
output_dir = Path("aimos/examples/paul_graham_essay/data/")
if response.status_code == 200:
os.system(f"mkdir -p {output_dir}")
with open(output_dir.joinpath("Paul_Graham_Essay.txt"), "wb") as file:
file.write(response.content)
else:
print("Failed to download the file.")3. Loading Document into LlamaIndex
The script reads the downloaded document using LlamaIndex's SimpleDirectoryReader and loads it into the system as a document.
documents = SimpleDirectoryReader(output_dir).load_data()4. Setting Up AimOS Callback for LlamaIndex Observer
aim_callback = GenericCallbackHandler(repo="aim://0.0.0.0:53800")
callback_manager = CallbackManager([aim_callback])Ensure that your AimOS server is active on the default 53800 port. In this instance, the server is running on the local machine. You can start an AimOS server with this simple command command:
aimos server5. Creating LlamaIndex Service Context
Here, we configure the LlamaIndex service context, create a vector store index using the loaded documents, and obtain a query engine for interacting with the index.
service_context = ServiceContext.from_defaults(callback_manager=callback_manager)
index = VectorStoreIndex.from_documents(documents, service_context=service_context)
query_engine = index.as_query_engine()6. Performing Queries and Flushing Callbacks
This section triggers queries on the LlamaIndex using the query engine and ensures that the callbacks are flushed, capturing the corresponding traces.
aim_callback.flush()
query_engine.query("How does Graham address the topic of competition and the importance (or lack thereof) of being the first mover in a market?")
aim_callback.flush()
query_engine.query("What are Paul Graham's notable projects or companies?")
aim_callback.flush()
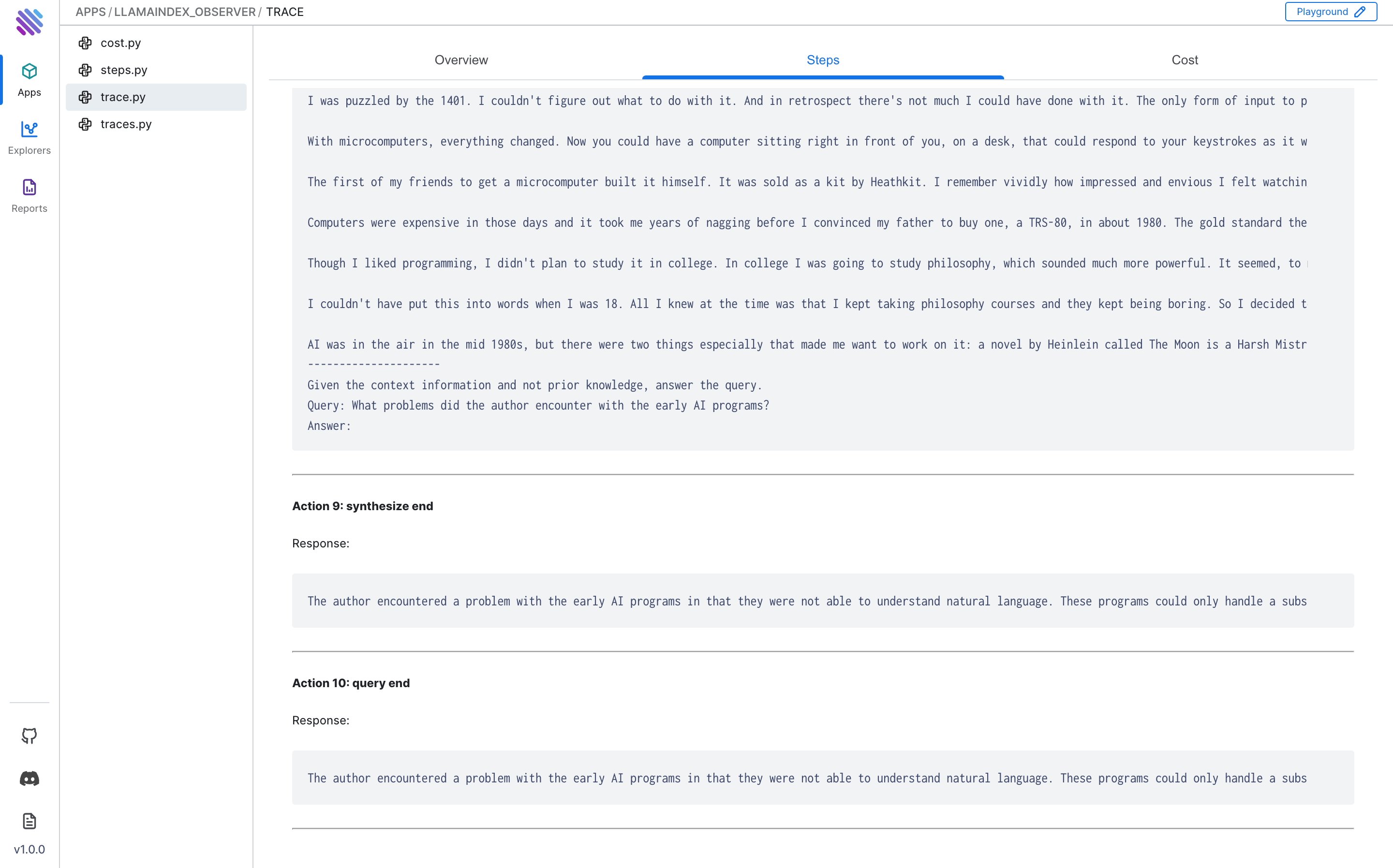
query_engine.query("What problems did the author encounter with the early AI programs?")
aim_callback.flush()After completing these steps, you will successfully log all actions on AimOS. Now, let's run the AimOS UI to observe the tracked metadata. To do this, navigate to the folder where the .aim repository is initialized and simply run.
aimos ui😊 Enjoy this preview of what you'll see once you visit the provided URL:

Navigate to the llamaindex_observer package under AI Systems Debugging.
Now, we will delve into the tracked information.
Interpreting the Results
Once you’ve run the script, go to the Traces page in AimOS. There, you'll find a new trace corresponding to each query in the script. You can get valuable information by checking the Overview, Steps, and Cost tabs. These will show you details about the script’s execution, token use, and the costs involved.

Overview Tab: A Quick Summary
The Overview tab in AimOS gives you a snapshot of what happened. Here are the main things you can see:
Trace ID: A unique identifier for each trace, allowing you to easily reference and analyze specific interactions.
Date and Time: Timestamps help you understand when actions took place, facilitating a chronological understanding of your LlamaIndex usage.
Total Steps: The number of actions or queries performed in a trace, providing a quick measure of complexity.
Total Tokens: Understand the computational load of your queries, ensuring optimal performance.
Cost: A critical factor in resource management, the cost breakdown helps you make informed decisions.

Understanding the Process
At the top of the Steps tab, you'll find a slider labeled "Select the step," enabling seamless navigation through the LlamaIndex processes. These steps are logged using the 'flush()' command.
Step 1: Chunking and Embedding
In the initial step, the provided essay document undergoes a chunking process, dividing it into multiple segments. Simultaneously, embeddings are extracted for each chunk, forming a foundational representation of the document's content.

Step 2: Query Processing
Question Formulation: A specific question is asked about the document, such as "How does Graham address the topic of competition and the importance of being the first mover in a market?"

Query Initiation: LlamaIndex initiates a query, retrieving the most relevant chunks from the previously embedded document.

Prompt Generation: A prompt for the language model is crafted. This involves combining the context strings (document chunks) and the question to create an input for the language model.

Language Model Response: The language model processes the prompt, generating a response that addresses the asked question.

Step 3: Iterative Questioning
While Step 1 is a one-time occurrence, our example involves asking three distinct questions. The process for generating responses to the second and third questions aligns with the methodology outlined in Step 2, utilizing the previously embedded chunks of the document.
The additional questions asked are:
- "What are Paul Graham's notable projects or companies?"

Generated response:

- "What problems did the author encounter with the early AI programs?"

Generated response:
Cost: Evaluating Resource Usage
In the Cost tab, you can examine three graphs showing token-usage, token-usage-input, and token-usage-output, providing a detailed breakdown of the computational costs associated with your LlamaIndex activities.
- On the x-axis, you can see the steps, which represent the number of times the system made an API request to an LLM (Language Model).
- On the y-axis, you can see the number of tokens sent or received.

Wrapping up
The “LlamaIndex Observer” in AimOS is a powerful tool for deepening your understanding of how your LlamaIndex models operate. It's great for both experienced users and beginners, offering a comprehensive observability of model performance.
For further insights into AI system monitoring and observability of software lifecycle, check out our latest article on the AimStack blog.
Learn more
AimOS is on a mission to democratize AI Systems logging tools. 🙌
Try out AimOS, join the Aim community, and contribute by sharing your thoughts, suggesting new features, or reporting bugs.
Don’t forget to leave us a star on GitHub if you think AimOS is useful, and here is the repository of Aim, an easy-to-use & supercharged open-source experiment tracker.⭐️